Just OLAP it: derive an OLAP data model from your OLTP ORM
TL;DR
- OLTP ≠ OLAP: OLTP systems optimize for correctness and per-row transactions; OLAP systems optimize for large-scale scans and aggregations. Their data modeling defaults are fundamentally different.
- Derive your OLAP ORM types from your OLTP ORM: Instead of trying to make your OLTP ORM speak OLAP, reuse its generated TypeScript types and layer OLAP-specific semantics in MooseOLAP (engines, ordering, partitioning, strict types).
- Make assumptions explicit: OLAP requires explicit choices around nullability, deduplication, and type strictness: defaults that are implicit in OLTP models.
- Result: You keep schema-as-code and type safety, while gaining OLAP-native performance and predictable behavior in ClickHouse.
Quick links: MooseStack. Demo repo. Docs.
Transactional ORMs are super valuable to many developers, their popularity makes that obvious. They have earned their spot because they turn your schema and queries into code you can type-check, review, version, and test. This article isn’t here to relitigate ORM v handwritten SQL; both are valid approaches with different strengths for different usages and users. The purpose of this article is to discuss how you can carry the benefits of ORMs into the analytics world if you want to go that route.
In TypeScript OLTP ORMs, like Drizzle and Prisma, types flow from table definition to queries to APIs, catching drift and type issues at compile time. Defining type-safe tables, queries and APIs are all super useful. Today, we’ll primarily focus on the first step: table/schema definition, using the types you have from your OLTP ORM to speed up the process.
In the blog posts to follow this week and next, we’ll cover extending these types to query definition and API definition with Moose APIs or your API framework of choice.
Recap of why OLTP ORMs are uncanny in an OLAP stack
If you want to go into further detail here, full blog here: https://clickhouse.com/blog/moosestack-does-olap-need-an-orm
 Much like “The Polar Express”, OLTP ORMs just feel a little bit wrong in an analytics context.
Much like “The Polar Express”, OLTP ORMs just feel a little bit wrong in an analytics context.
Transactional databases are written for atomicity and correctness. The primary form of interaction with these databases is finding particular transactions and reading or mutating them. Since you are only returning or dealing with few rows, the efficiency of each column isn’t as critical, so you can make certain data modeling decisions for ease of use and flexibility:
- defaulting to columns being nullable (in ClickHouse, it is significantly more efficient for your columns to use default values rather than to be nullable)
- defaulting to permissive types for ease of use (in OLAP, strict types have enormous performance and storage benefits, especially given the volume they typically see)
- enforcing uniqueness at write (in ClickHouse, you use table engines to achieve this)
- indexing for retrieval rather than for scanning (see best practices on partitioning and ordering your data)
- normalizing your data for correctness at read time and storage efficiency (in OLAP, “schema on write” dramatically improves query performance, see denormalization, data modeling and JSON nestedness best practices).
These are not shallow assumptions, they are fundamentally built into the types that you create with your OLTP ORMs.
This article therefore proposes that you should not stretch your OLTP ORM into OLAP: doing so will bring all the assumptions you have in OLTP into the OLAP world.
Rather, use the types you create with your OLTP ORM, and add explicit OLAP semantics in MooseOLAP. This will reduce double-work, and tie your two systems together (even allowing you to add a full analytics stack to your existing transactional monorepo), while still being able to use OLAP best practices in your data modeling, as well as ClickHouse specific table configurations when creating your tables.
“Just OLAP your ORM” (Drizzle to MooseOLAP)
Steps:
- Create a generic typescript type from your OLTP ORM (with Drizzle, using
$inferSelecttype inference helper) - Extend that model to be OLAP flavored
- Use Moose types in defining MooseOLAP tables
When working on our CDC demo application last week, we used Drizzle to model the data in our postgres database. We then recycled much of the typescript type definitions in our OLAP back-end with MooseStack.
Raw Drizzle Postgres table definition
debezium-cdc/app/oltp/schema.ts
This defines the customerAddress constant, which is used by Drizzle to create the Postgres tables. You can see some of those OLTP assumptions in this data model, like default nullables, primary keys, etc.
Extract generic TypeScript type
Below that, we exported the native TypeScript type CustomerAddress, using Drizzle’s $inferSelect type-inference helper (note, the mechanism for extracting this native type differs per ORM, we’ll go over a few in appendices):
debezium-cdc/app/oltp/schema.ts
Which gives us the following:
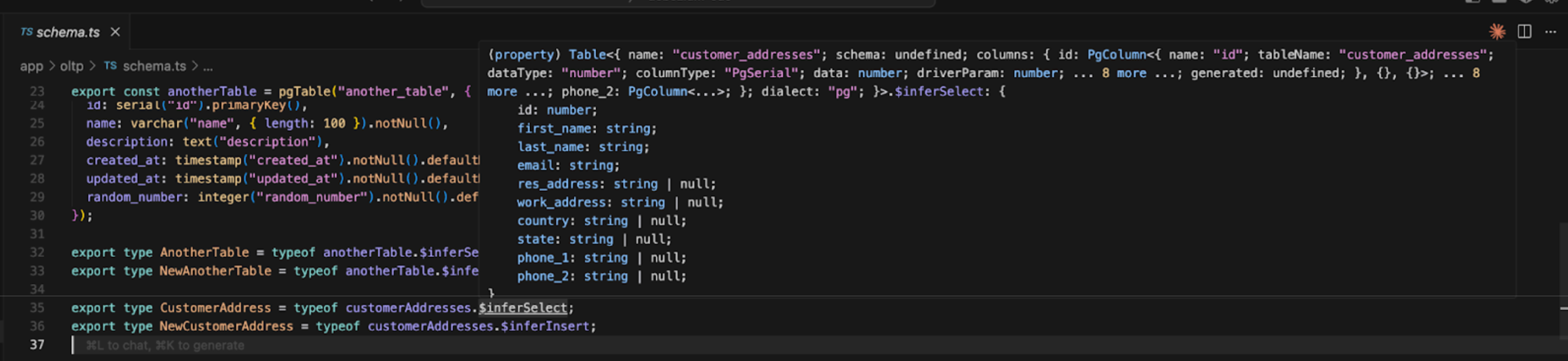
Extracted for readability:
This loses some fidelity from the Drizzle-specific properties used (like length: 100 and varchar v text ), but gives TS native types which can be used more broadly.
Ideally, we don’t want to lose this original context, and while you can manually transfer advanced types to your MooseOLAP model, it’s even more fun to have an LLM/co-pilot do it for you!
Create an OLAP flavored TypeScript object using MooseOLAP
We can now use this type to create an object that is defined in an analytical context, without having to start from scratch:
This takes the original type extracted from the Drizzle definition and does two things:
- Adds fields necessary for ClickHouse’s
ReplacingMergeTreeto deduplicate the CDC data properly:& CDCFields - Inherits as much from the source data model as possible, but modifies it for best practices in OLAP (by
Omit<>+&), using strict types, default values, and appropriate nulls
In that demo application, this type was used in a few places related to data modeling and transformation:
- Moose Stream transformation functions and sink topics to conform the data extracted from Postgres with CDC to this data model, and
- in creating the ClickHouse tables to land the data in.
Create your ClickHouse table with MooseOLAP
The final step is to declare the OLAP table with this new type:
debezium-cdc/app/cdc/3-destinations/olap-tables.ts
This uses the new OlapCustomerAddress type, created from the CustomerAddress type used with Drizzle in Postgres, to create a table in ClickHouse that makes use of ClickHouse’s features. It does this with MooseOLAP’s OlapTable object, which takes the data model object in, and is then configured for use with ClickHouse’s ReplacingMergeTree.
AI and data modeling
We found in creating the above, and in working with our customers that giving a copilot some sample data, the source ORM types, and OLAP best practices agent docs, they were able to generate:
- TypeScript models that conform with OLAP best practices from sources (with restrictive types, nullability replaced with default values, denormalized flattened data, etc.)
- Defined streaming functions that conform incoming data to the form expected by the destination table
But “OLTP ORM’s shouldn’t be extended to OLAP”
They shouldn’t! The systems are very different; we wrote a whole blog post about it. These differences aren’t quirks. They’re baked into how OLTP and OLAP systems work. So instead of forcing your ORM to do both jobs, MooseOLAP lets you reuse your ORM’s native typescript types while handling OLAP modeling and table management in its own layer.
The following are by way of example:
| OLTP v OLAP issue | What we don’t do | What we do instead |
|---|---|---|
Defaulting to nullable in OLTP and not nullable in OLAP means .notNull() means different things in your OLAP and OLTP contexts | Reuse OLTP ORM modifiers verbatim | Treat nullability as explicitly: choose Nullable(T) only when needed; offer default values and other OLAP best practices here |
.unique() being write-time in OLTP, relatively meaningless in OLAP at write time | Remap .unique() magically | Make deduplication explicit: ReplacingMergeTree(version) + ORDER BY |
| Indexes in OLTP are not the same as sort and partition keys in OLAP | Map indexes to ORDER BY | Choose ORDER BY and PARTITION BY explicitly in declaring your OlapTable |
Appendix: Other ORMs
Here’s a lightweight guide to getting to the same place with other ORMs:
Prisma
Step one: your Prisma data model
Prisma defines tables as schema models in the schema.prisma file. These models describe both your database structure and the TypeScript types that Prisma generates.
Step two: extract TypeScript default models
When you run prisma generate, Prisma’s client generates strongly typed models. To get a plain TypeScript type, you can use the built-in Prisma.<Model>GetPayload helper:
That gives you native TypeScript types from your schema.
From here, everything else (extending for OLAP semantics and creating your OlapTable) is the same as in the Drizzle example.
TypeORM
Step one: original model.
TypeORM defines tables as decorated classes.
Step two: extract TypeScript default models
If you want a pure TypeScript type (for example, to pass into MooseOLAP), you can use the InternalType<> utility provided by TypeORM:
For models that include relationships (@ManyToOne, @OneToMany), you’d typically Omit those fields when preparing your OLAP type:
This keeps your OLAP model clean, containing only scalar fields. From here, everything proceeds as in the Drizzle example. Extend your type with OLAP-specific fields and define your OlapTable.
What about the rest of an ORM’s functionality?
Data modeling is only one of the core value propositions of ORMs. In the following blog posts over the next two weeks, we’ll cover the transformation and consumption layers, and using the MooseOLAP objects that we extracted today with them.
What about Python ORMs?
Tune in tomorrow.
Interested in learning more?
Sign up for our newsletter — we only send one when we have something actually worth saying.
Related posts
All Blog Posts
OLAP
OLAP migration complexity is the cost of fast reads
In transactional systems, migrations are logical and predictable. In analytical systems, every schema change is a physical event—rewrites, recomputations, and dependency cascades. This post explains why OLAP migrations are inherently complex, the architectural trade-offs behind them, and how to manage that complexity.

OLAP, Product
Ship your data with Moose APIs
You’ve modeled your OLAP data and set up CDC—now it’s time to ship it. Moose makes it effortless to expose your ClickHouse models through typed, validated APIs. Whether you use Moose’s built-in Api class or integrate with Express or FastAPI, you’ll get OpenAPI specs, auth, and runtime validation out of the box.