Building Data-Intensive Features: The Inevitable Pain of OLAP Re-Architectures
Published Fri, January 24, 2025 ∙ Data Products, Educational, Data Intensive Features ∙ by Johanan Ottensooser
*Aurora has been rebranded Sloan. See Sloan docs here: docs.fiveonefour.com/sloan
Executive Summary
- Data-Intensive Features (DIFs) become essential but quickly outgrow transactional databases, leading to performance bottlenecks.
- Shifting to OLAP is inevitable for scalable analytics, yet rearchitecting midstream can be time-consuming, costly, and painful.
- Fiveonefour’s Moose, Boreal, and Aurora streamline OLAP adoption by automating data engineering, hosting, and AI-driven code generation.
- Result: Faster time-to-market for analytics-driven products, less technical debt, and the flexibility to introduce or start with OLAP whenever needed.
Organizations everywhere are looking to differentiate their applications by offering data-intensive features (DIFs). Leaderboards, interactive dashboards, personalized recommendations, AI-driven analytics, and other data-informed capabilities have become both competitive necessities and powerful value-adds. However, for many teams, the journey from an MVP running on a simple relational database to an application with seamless analytics can be riddled with performance bottlenecks and mounting technical debt. This post examines that all-too-common journey and explores how Fiveonefour’s offerings—Moose, Boreal, and Aurora—can ease or even preempt the painful rearchitecture process.
The Lifecycle of Data Intensive Features
Stage 1: “Start Simple”
When building an application from scratch, speed is of the essence. Most teams initially opt for the least “heavy” data infrastructure possible—usually a familiar relational database such as MySQL or PostgreSQL. This approach makes sense: no one wants to risk slowing down core development by introducing complex analytics engines or OLAP systems before they’ve validated the core product idea. In this initial phase, agility and time-to-market take priority over everything else.
And for a while, it works. New features get shipped rapidly. The development team can easily handle transactional queries and a handful of reports or dashboards. Stakeholders remain happy with the velocity of product releases. But as the application matures and the business discovers the potential of data-intensive features, everything starts to change.
Stage 2: One Straw, and Then the Last Straw
Once the product gains traction, the focus shifts. Internal stakeholders and customers alike begin demanding data-rich experiences:
- “Can we add a dashboard showing user trends?”
- “Let’s create an AI-driven recommendation engine!”
- “Our customers want to see comparative analytics on their performance.”
Product teams realize their users want more insights from the data they’re collecting—maybe in the form of advanced reporting, real-time analytics, or AI-driven suggestions. Or perhaps they see a market advantage in embedding data visualizations into the user interface. These data-intensive features often involve aggregations, complex joins, or large-scale computations that demand far more from the database than it was ever designed to handle.
At first, the team may attempt to power these features directly from the existing relational infrastructure. But these systems are optimized for transactional workloads—tracking orders, managing user profiles, or storing simple logs. Analytical queries, especially those scanning large datasets or performing multiple grouping operations, quickly degrade performance. Not only do these queries take too long to deliver insights; they can also slow core transactional activity to a crawl, compromising the overall user experience.
Technical aside: why pivot to OLAP here? Why can’t the OLTP databases that we prototyped with work at scale for analytics use-cases?
- Query Complexity Amplification: Analytical queries inherently differ from transactional queries in their computational requirements. While transactional queries typically involve precise, targeted data retrieval, analytical queries demand complex aggregations, multi-table joins, and comprehensive data scans.
- Index Inefficiency: Traditional relational databases optimize indexes for transactional workloads, which become increasingly ineffective for analytical queries. As data volumes grow, these indexes create significant overhead during complex aggregation and reporting operations.
- Shared Resource Contention: Analytical queries compete directly with transactional queries for the same computational resources. A complex reporting query can dramatically slow down critical user-facing operations, creating a cascading performance degradation.
- Vertical Scaling Limitations: As teams attempt to improve performance by adding computational resources, they encounter diminishing returns. The cost of vertical scaling becomes exponentially inefficient compared to horizontal, distributed approaches.

Stage 3: the Spectre of Re-architecture
When the need for better analytics performance becomes impossible to ignore, teams commonly pivot to an OLAP (Online Analytical Processing) architecture. They might adopt a data warehouse or specialized analytics database.
This often requires work that usually falls outside of the product team that originally built the product—relying on the central data teams. This is also usually a multi-quarter exercise.
Technical aside: the work of an OLAP rearchitecture takes so long because it requires:
-
Standing Up New Infrastructure
Managing a separate analytics database or cluster can be complex, involving careful provisioning, tuning, and ongoing maintenance.
-
Building Data Pipelines
Data has to be transformed, cleaned, and synced from the transactional database into the OLAP store. Creating these pipelines and managing their reliability can be a major new engineering undertaking.
- Data Extraction and Transformation: Developing robust Extract, Transform, Load (ETL) processes that can accurately and efficiently move data between transactional and analytical systems.
- Schema Redesign: Fundamentally rethinking data models to support analytical query patterns, often involving denormalization and pre-aggregation strategies.
- Synchronization Mechanisms: Creating real-time or near-real-time data synchronization processes that ensure analytical systems reflect the most current transactional state.
-
Restructuring the Application Layer
Product features originally built against the transactional database need to be rewritten to interface with the OLAP system and handle potential latency differences or data inconsistencies.
- Query Layer Abstraction: Implementing middleware or virtualization layers that can intelligently route queries to the most appropriate data store.
-
Coordinating Cross-Functional Priorities
If the data-intensive feature isn’t high-priority, it’s hard to justify the months-long rearchitecture compared to other product initiatives. But if it is high-priority, pulling engineering resources into a major overhaul can still stall feature delivery and disrupt roadmaps.
This tension, combined with the underlying complexity of big data technology, turns OLAP adoption into an expensive and time-consuming project. While no one expects an MVP to start with a full-blown data warehouse, the technical debt that accrues from deferring the adoption of an OLAP solution is painful to pay down.
Breaking the Cycle With Fiveonefour
At Fiveonefour, we believe OLAP rearchitecture doesn’t have to be a slog. Our product suite is designed to help development teams integrate (or start with) modern analytics capabilities without sacrificing time-to-market or incurring untenable levels of technical debt.
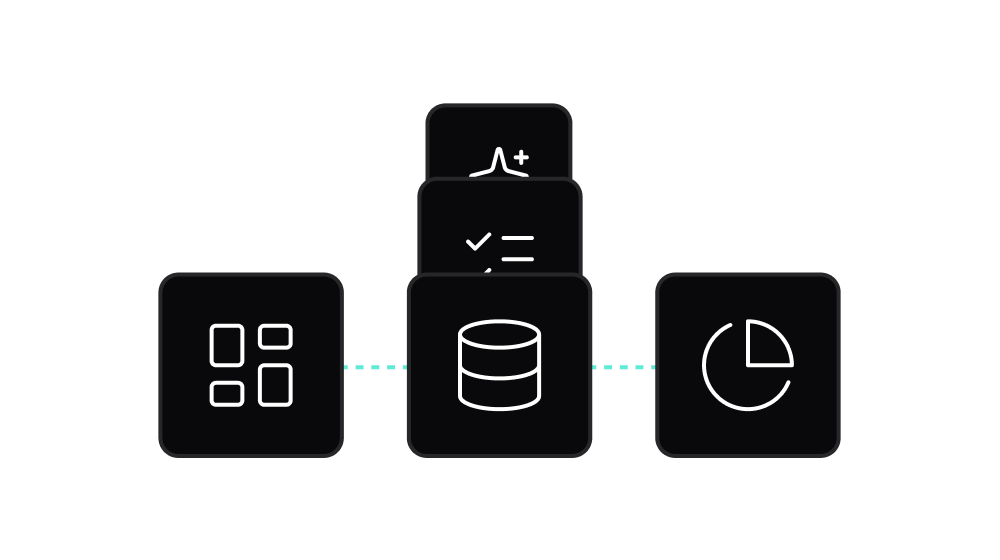
- Moose being the open source, declarative developer framework for data engineering workflows
- Boreal being the scalable, secure hosting platform for Moose applications
- And Aurora, the agent based AI tool for creating the above.
This allows for:
1. Less Painful Retrofitting
Moose, our open-source developer framework, wraps and abstracts away complex data engineering tasks. Instead of juggling multiple platforms for your transactional and analytical workloads, you can integrate Moose into your existing codebase in a more incremental, controlled manner. It provides a convenient abstraction layer, making it simpler to build pipelines, manage transformations, and connect your app to an efficient analytics backend.
Meanwhile, Boreal, a scalable and secure hosting platform for Moose applications, ensures that you don’t have to wrestle with infrastructure overhead. It gives you a managed environment to host and run your Moose-based analytics, reducing the operational burden.
2. Introduce OLAP Earlier in the Lifecycle
If you see DIFs as strategic differentiators, there’s strong motivation to implement an OLAP solution earlier—before your existing databases and code become too entrenched. Yet, development teams often balk at this idea, assuming it will mean more overhead at an early stage.
With Moose, you can scaffold an OLAP-enabled architecture without a massive upfront time investment. By leveraging Aurora, our agent-based AI system, you can generate much of the necessary data stack code automatically. Aurora’s guidance helps streamline the creation of your analytics pipeline and ensures best practices are followed from the start. Essentially, you gain the best of both worlds: rapid application development and a modern analytics foundation that scales.
3. Start With an OLAP + OLTP Hybrid for DIF-Focused Products
Some products are built around data-driven experiences from day one—think advanced analytics products, business intelligence solutions, or AI-driven platforms. If your core value proposition revolves around robust data insights, it may be worthwhile to start with an OLAP approach. The friction typically associated with OLAP is greatly reduced when your development framework, hosting, and code generation are all designed to handle analytical workloads natively.
Moose’s developer-friendly abstractions let your team focus on building features, not plumbing. Boreal handles the production hosting complexity, and Aurora speeds up coding new analytics features. This can make an OLAP+OLTP hybrid architecture feasible even at the earliest stages of product development.
Conclusion
No organization starts with a fully fledged OLAP solution in place; it often feels like a premature optimization. Yet the technical debt that accumulates as you shoehorn data-intensive features into a transactional system can become a severe liability. By the time analytics truly matter, rearchitecting around a specialized OLAP environment requires months of data engineering and infrastructure changes—slowing down product roadmaps and draining resources.
That’s where Fiveonefour’s approach changes the equation. Our tools—Moose, Boreal, and Aurora—make OLAP integration:
- Less painful if you’re already at the breaking point.
- So much easier that you can adopt OLAP earlier in your product’s lifecycle.
- Entirely feasible to start with from day one if DIFs are central to your offering.
As demand for embedded analytics, data-driven experiences, and AI-driven features continues to grow, organizations can’t afford to let technical debt hold them back. By embracing a forward-thinking, developer-friendly OLAP strategy, you can future-proof your application and deliver rich, data-intensive features that delight users—without the headaches of traditional rearchitectures.
Learn more about how Moose, Boreal, and Aurora can transform your data stack by visiting fiveonefour.com. If you’re ready to abstract away the complexity of OLAP and accelerate your time-to-insight, explore Moose, or take a look at Boreal and Aurora. Let’s make data-intensive features a competitive advantage—without the pain.
Appendix: DIF for Industry
Different industries face unique challenges when implementing data-intensive features:
E-commerce and Retail
E-commerce platforms require real-time inventory analytics, personalized recommendations, and dynamic pricing. Traditional architectures struggle with computing these features across millions of products and transactions.
Example Challenge: Computing real-time inventory turnover rates across thousands of SKUs while maintaining sub-second response times for product pages.
Financial Services
Financial applications need to process historical transaction data for fraud detection, risk assessment, and regulatory reporting. These applications often deal with years of transaction history and complex compliance requirements.
Example Challenge: Calculating risk metrics across millions of transactions while maintaining ACID compliance for core banking operations.
SaaS Applications
Software-as-a-Service providers need to offer customizable analytics dashboards to their customers while ensuring tenant isolation and maintaining performance at scale.
Example Challenge: Providing custom report builders that can handle complex queries across isolated customer datasets without impacting application performance.
Gaming and Entertainment
Gaming platforms require real-time leaderboards, player statistics, and matchmaking systems that can process massive amounts of game data without introducing latency.
Example Challenge: Updating global leaderboards in real-time while processing millions of game events per second.